There are several machine learning algorithms. Some of the most popular are used for regression, reinforcement, clustering and classification.


In my previous article Artificial Neural Networks Regression and Classification, I introduced the three types of problems that machine learning is generally used to solve:
In that article, I focus on solving classification and regression problems. In this article, I turn my attention to neural network clustering problems — problems that can be solved by identifying common patterns among inputs.
Clustering has numerous applications in a wide variety of fields. Here are a few examples of how clustering may be used:
Unlike classification and regression problems, which employ supervised learning, clustering problems rely on unsupervised learning. With supervised learning, you have clearly labeled data or categories that you are trying to match inputs to. For example, you may want to classify homes by price or classify transactions as fraudulent or honest.
Unfortunately, supervised learning is not always an option. For example, if you do not have clearly labeled data or know the categories into which you want to sort the data inputs, you cannot engage your artificial neural network in supervised learning. In other applications, you may not be interested in classifying your data into categories created by humans; instead, you want to see how your neural network clusters the data to call your attention to patterns you may never have thought to look for.
In such cases, unsupervised learning is the better choice. With unsupervised learning, you let the neural network cluster your data into different groups.
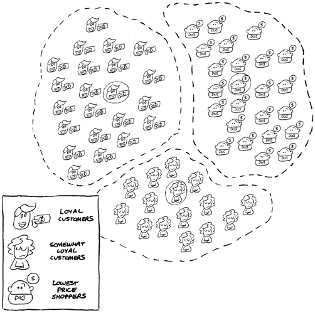
One of the more interesting applications of clustering is its use by large retailers to decide whom to invite to their loyalty programs or when to offer promotions. With unsupervised learning, the machine may identify three clusters of customers — loyal, somewhat loyal, and not loyal. (The not loyal customers always buy from whichever retailer offers the lowest price.) Knowing these clusters, the large retailers create strategies to try and elevate somewhat loyal customers to loyal customers. Or they could invite their loyal customers to participate in special promotions.
Other companies use clustering to decide where to place new stores. For example, a seller of athletic footwear may feed demographic and sales data into an artificial neural network to find locations that have the highest concentration of active runners or locations where customers allocate a higher percentage of their income to outdoor recreation.
When you decide to use machine learning to solve a problem, what is most important is that you choose the right approach for the problem you are trying to solve. Classification is great when you know what you are looking for and can teach the machine the relationship between inputs and labels or between independent variables and a dependent variable. Clustering is a more powerful tool for gaining insight — for seeing things in a different way, a way you may never have considered or when you have a high volume of unlabeled data you want to analyze. After all, there is much more unlabeled (unstructured) data available than there is labeled (structured) data.
When you’re trying to decide which approach to take — classification, regression, or clustering — first ask yourself what problem you’re trying to solve or what question you need to answer. Then ask yourself whether the problem or question is something that can best be addressed with classification, regression, or clustering. Finally, ask yourself whether the data you have is labeled or unlabeled. By answering these questions, you should have a clearer idea of which approach to take: classification or regression (with supervised learning) or clustering (with unsupervised learning).
There are several machine learning algorithms. Some of the most popular are used for regression, reinforcement, clustering and classification.
In data science the difference between data mining vs machine learning is a key concept.
In machine learning, you often have to create an ensemble by combining algorithms in your learning model.