Turing's imitation game considers the question of whether an artificial intelligence agent is truly intelligent. Alan Turing proposed this to test the computing power of artificial general intelligence.

In my previous article, Machine Learning Algorithms, I explain what machine-learning algorithms are and describe the following commonly used algorithms:
Based on the descriptions of the machine learning algorithms I presented in that post, you could already start to figure out which algorithm would be best for answering a certain type of question or solving a certain type of problem. In this article, I provide some additional guidance.
Your choice of algorithm generally depends on what you want the algorithm to do:
When choosing an algorithm, consider a more empirical (experimental) approach. After narrowing your choice to two or more algorithms, you can train and test the machine using each algorithm with the data you have and see which one delivers the most accurate results. For example, if you're looking at a classification problem, you can run your training data on K-nearest neighbor and Naïve Bayes and then run your test data through each of them to see which one is best able to accurately predict which class a particular unclassified entity belongs to.
There is a more formal method for choosing a machine-learning algorithm, as presented in the following sections.
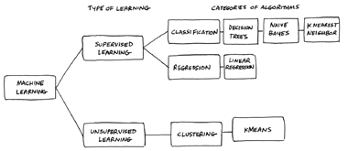
The first step is to figure out the nature of the problem you are trying to solve via machine learning. Categorize the problem by both input and output:
1. Categorize the problem by input:
2. Categorize the problem by output:
The data you have also informs your choice of machine-learning algorithm:
Conditions beyond your control may influence your choice of machine-learning algorithm. For example:
Also, ask the following questions:
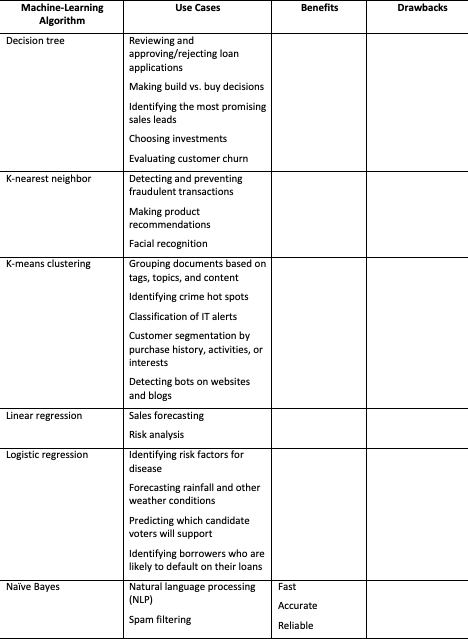
The final step involves making your choice. The following table provides a list of algorithms along with specific use cases in which each application may be most suitable, as well as the pros and cons of each algorithm.
Remember, prior to building a machine learning model, it is always wise to consult others on your data science team, particularly your resident data scientist, if you are fortunate enough to have one. Choosing a machine learning algorithm is a combination of art and science, so you’re likely to benefit by having someone look at the problem from another perspective.
Turing's imitation game considers the question of whether an artificial intelligence agent is truly intelligent. Alan Turing proposed this to test the computing power of artificial general intelligence.
Overcome artificial intelligence challenges and embrace data science as a way to get value from AI and machine learning.
The General Problem Solver In a previous post entitled "Playing the Imitation Game," I discussed Alan Turing's vision, published in 1936, of a single, universal machine that could be programmed to solve any particular problem. In 1959, Allen Newell and Herbert A. Simon took a different approach. Their goal was to develop a computer program […]