Data science teams do more than just analytics and reports. They need to discover insights about your data.

Data modeling is the process of defining the structure, flow, and relationships of data stored in a database management system (DBMS). A data model provides the framework for all the data an organization generates and stores, and it facilitates the process of extracting, combining, and analyzing that data later. The goal of the data modeling process is to define the following:
A simple example of a data model is a spreadsheet with customer contact information. Row and column headings label every data entry, and data validation can be used to constrain data; for example, you can limit text entries to a certain number of characters. In practice, however, data models are much more complex, typically consisting of hundreds of individual tables that are related to one another in various ways.
A data model ensures that an organization’s data is structured — meaning that all data entries are clearly labeled and in a consistent format. Structuring data ensures consistency in naming conventions, default values, and data entry formats.
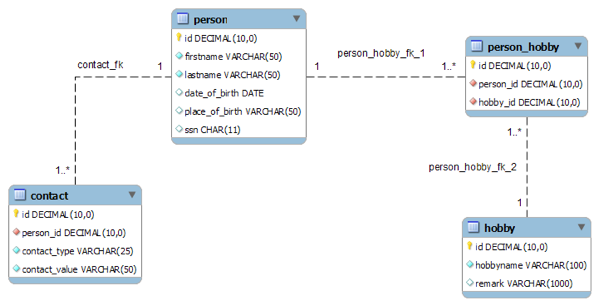
To build a data model, data architects must work closely with everyone in the organization responsible for entering data into the system as well everyone who will be using the information system to extract data, conduct analysis, generate reports, and so on. Only the people who enter data into the system and use that data to develop and execute the organization’s strategy know what the data model must contain.
The process of developing a data model typically involves the following steps:
Additional steps are required to address access, storage, and performance requirements.
The data modeling process is broken down into three stages or levels:
Ideally, a data architect takes a top-down approach to data modeling — gathering input from people in various departments to develop a conceptual model for capturing data and storing it in the organization’s DBMS.
However, a data architect may also take a bottom-up approach, starting with existing forms, fields, software, and reports to reverse-engineer a data model from an organization’s existing system.
One of the key benefits of data modeling is that it helps to ensure data integrity — accuracy and reliability, both in terms of entity integrity and referential integrity:
Normalization is the process of systematically breaking down a large, complex table into smaller ones to eliminate disparities and redundancy, thus improving data integrity while making the DBMS easier to manage. For example, by creating separate tables for customer data and order data, if a customer moves to a new address, you simply make that change in the customer table, and the change is automatically reflected in any new orders the customer places. You don’t have to make the change in the customer table and the order table, which would require more work and more storage and be more susceptible to introducing data discrepancies in the system.
Of course, data modeling is much more complex and involved than what I describe here, but this post provides a basic understanding to get you started. Keep in mind, however, that not all data an organization needs is as structured as its internal data. For business intelligence, organizations often rely on semi-structured and unstructured data, a topic I will cover in a later post.
Data science teams do more than just analytics and reports. They need to discover insights about your data.
Data critical thinking is a key skill for your team to get the most from data reports and analysis.
Data scientists will present analytics data as facts, but you need to challenge the data science evidence to see what assumptions the team is making.