Run data analytics sprints so your data science team can benefit from the short iterations you see in software development sprints.


Data science, artificial intelligence (AI), and machine learning (ML) are very complex fields. Amidst this complexity, it is easy to lose sight of the fundamental challenges to executing a data science initiative. In this article, I take a step back to focus less on the inner workings of AI and ML and more on the artificial intelligence challenges that often lead to mistakes and failed attempts at weaving data science into an organization's fabric. In the process, I explain how to overcome these key challenges.
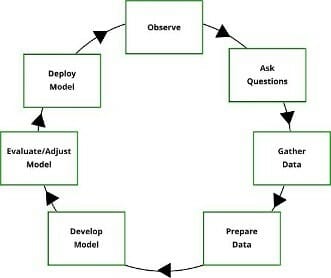
The term "data science" is often misinterpreted. People tend to place too much emphasis on "data" and too little on "science." It is important to realize that data science is rooted in science. It is, or at least should be, exploratory. As you begin a data science program, place data science methodology at the forefront:
Even the most basic artificial neural networks require large volumes of relevant data to enable learning. While human beings often learn from one or two exposures to new data or experiences, modern neural networks are far less efficient. They may require hundreds or thousands of relevant inputs to fine-tune the parameters (weights and biases) to the degree at which the network's performance is acceptable.
To overcome this limitation, AI experts have developed a new type of artificial neural network called a capsule network — a compact group of neurons that can extract more learning from smaller data sets. As of this writing, these networks are still very much in the experimental phase for most organizations.
Until capsule networks prove themselves or some other innovation enables neural networks to learn from smaller data sets, plan on needing a lot of high-quality, relevant data.
If you are lacking the data you need, consider obtaining data from external sources. Free data sources include government databases, such as the US Census Bureau database and the CIA World Factbook; medical databases, such as Healthdata.gov, NHS health, and the Social Care Information Centre; Amazon Web Services public datasets; Google Public Data Explorer; Google Finance; the National Climatic Data Center; The New York Times; and university data centers. Many organizations that collect data, including Acxiom, IRI, and Nielsen, make their data available for purchase. As long as you can figure out which data will be helpful, you can usually find a source.
There are two approaches to machine learning — supervised and unsupervised learning. With supervised learning, you need two data sets — a training data set and a testing data set. The training data set contains inputs and labels. For example, you feed the network a picture of an elephant and tell it, "This is an elephant." Then, you feed it a picture of a giraffe and tell it, "This is a giraffe." After training, you switch to the testing data set, which contains unlabeled inputs. For example, you feed the network a picture of an elephant, and the network tells you, "It's an elephant." If the network makes a mistake, you feed it the correct answer, and it makes adjustments to improve its accuracy.
Sometimes when a data science team is unable to acquire the volume of data it needs to train its artificial neural network, the team mixes some of its training data with its test data. This workaround is a big no-no; it is the equivalent of giving students a test and providing them with the answers. In such a case, the test results would be a poor reflection of the students' knowledge. In the same way, an artificial neural network relies on quality testing to sharpen its skills.
The moral of this story is this: Don’t mix test data with training data. Keep them separate.
When choosing training and test data for machine learning, select data that is representative of the task that the machine will ultimately be required to perform. If the training or test data is too easy, for example, the machine will struggle later with more challenging tasks. Imagine teaching students to multiply. Suppose you teach them multiplication tables up to 12 x 12 and then put problems on the test such as 35 x 84. They’re not going to perform very well. In the same way, training and test data should be as challenging as what the machine will ultimately be required to handle.
Also, avoid the common mistake of introducing bias when selecting data. For example, if you’re developing a model to predict how people will vote in a national election and you feed the machine training data that contains voting data only from conservative, older men living in Wyoming your model will do a poor job of predicting the outcome.
Machine learning is a powerful tool, but it’s not always the best tool for answering a question or solving a problem. Here are a couple other options that may lead to better, faster outcomes depending on the nature of the question or problem:
As you introduce data science, artificial intelligence, and machine learning to your organization, remain aware of the key challenges you face, and avoid getting too wrapped up in the technologies and toolkits. Focus on areas that contribute far more to success, such as asking interesting questions and using your human brain to approach problems logically. Artificial intelligence and machine learning are powerful tools. Master the tools; do not let them master you.
Run data analytics sprints so your data science team can benefit from the short iterations you see in software development sprints.
The perceptron history starts with Frank Rosenblatt and the earliest work on artificial neural networks. This was some of the earliest steps in artificial intelligence.
Data science is a multi-disciplinary approach to extracting insight from data. The disciplines involved include computer science/information technology, math/statistics, and domain knowledge/expertise (for example, knowledge of a specific industry). The process of extracting insight from data is typically broken down into the following five stages: Shifting the Focus from Data to Science The best way […]