Machine learning is one of the best ways to gain insights from your big data. See how you should approach this data science challenge.


In my previous article, Neural Network Hidden Layers, I presented a simple example of how multi-layer artificial neural networks learn. At a more basic level is the perceptron — a single-layer neural network. The perceptron history is worth looking at because it sheds light on how individual neurons within a neural network function. If you know how a perceptron functions, you know how an artificial neuron functions.
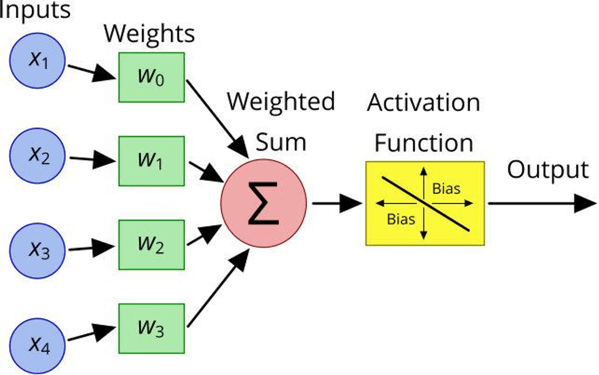
A perceptron consists of five components:
Basically, here's how a perceptron works:
Weights and bias are primarily responsible for enabling machine learning in a neural network. The neural network can adjust the weights of the various inputs and the bias to improve the accuracy of its binary classification system.
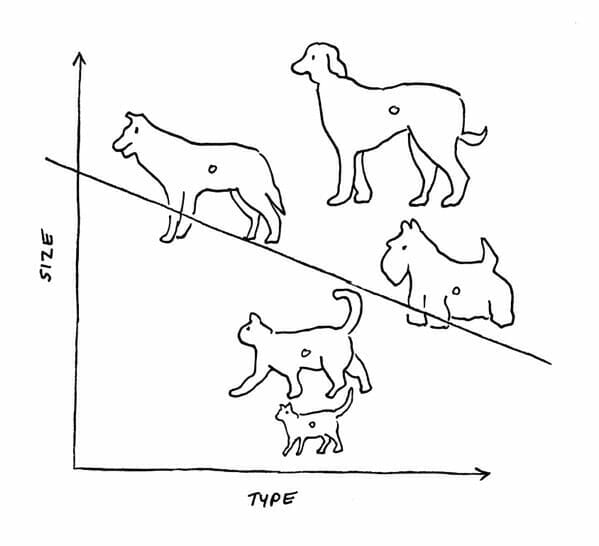
For example, the figure below illustrates how the output function of a perceptron might draw a line to distinguish between pictures of cats and dogs. If one or more dog pictures ended up on the line or slightly below the line, bias could be used to adjust the position of the line so it more precisely separated the two groups.
Frank Rosenblatt invented the perceptron in 1958 while working as a professor at Cornell University. He then used it to build a machine, called the Mark 1 Perceptron, which was designed for image recognition. The machine had an array of photocells connected randomly to neurons. Potentiometers were used to determine weights, and electric motors were used to update the weights during the learning phase.
Rosenblatt's goal was to train the machine to distinguish between two images. Unfortunately, it took thousands of tries, and even then the Mark I struggled to distinguish between distinctly different images.
While Rosenblatt was working on his Mark I Perceptron, MIT professor Marvin Minsky was pushing hard for a symbolic approach. Minsky and Rosenblatt debated passionately about which was the best approach to AI. The debates were almost like family arguments. They had attended the same high school and knew each other for decades.
In 1969 Minsky co-authored a book called Perceptrons: An Introduction to Computational Geometry with Seymour Papert. In it they argued decisively against the perceptron, showing that it would only ever be able to solve linearly separable functions and thus be able to distinguish between only two classes. Minsky and Papert also, mistakenly, claimed that the research being done on the perceptron was doomed to fail because of the perceptron's limitations.
Sadly, two years after the book was published, Rosenblatt died in a boating accident. Without Rosenblatt to defend perceptrons and with many experts in the field believing that research into the perceptron would be unproductive, funding for and interest in Rosenblatt's perceptron dried up for over a decade.
Not until the early 1980s did interest in the perceptron experience a resurgence, with the addition of a hidden layer in neural networks that enables these multi-layer neural networks to solve more complex problems.
Machine learning is one of the best ways to gain insights from your big data. See how you should approach this data science challenge.
Most people are afraid of artificial intelligence for the wrong reasons. It probably won't be killer robots, but machine learning might make quick and transformative changes.
Examples of machine learning applications that are designed to solve complex business challenges.