Extract Transform Load (ETL) comes from data warehousing. The ETL process is about getting data from multiple data sources and using an ETL tool to extract value.


In my previous post, "The Data Science Life Cycle (DSLC)," I encourage you to adopt a structure for your data team's activities that is conducive to the type of work it does — exploration. I refer to this structure as the Data Science Life Cycle (DSLC), illustrated below.
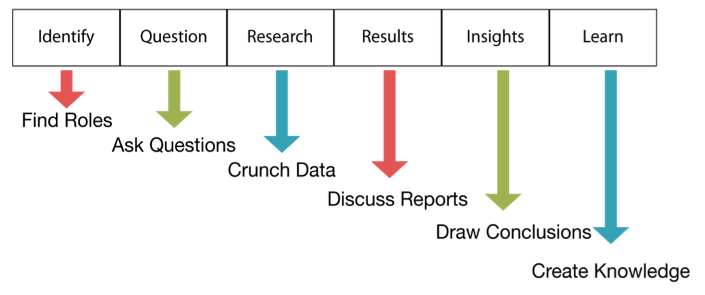
At first glance, DSLC appears to be a linear process, starting with identification and ending with learning, but the process is actually cyclical. Learning leads to more questions that return the team to the beginning of the process. In addition, mini-cycles often form within the DSLC as research and analysis results prompt questions that require additional research and analysis to answer, as shown below.

In this post, I drill down to illustrate how data science teams can function more effectively and efficiently within the DSLC framework by employing the following techniques:
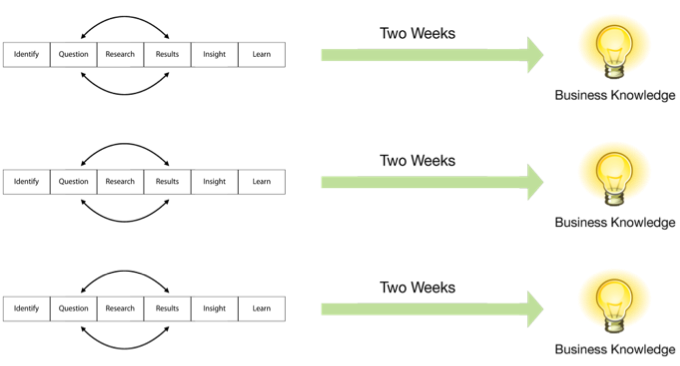
The DSLC isn’t designed to cycle over a long period of time. Two weeks is sufficient for a cycle (a sprint). That gives the team sufficient time to prepare and analyze the data and compose a story that reveals the knowledge and insight extracted from the data and its significance to the organization. With short cycles, if a specific line of enquiry proves fruitless, the team can change course and head in a different direction or tackle a new challenge.
You may have heard of sprints in the context of agile software development methodologies, such as Scrum, but the term actually originated in product development. A sprint is a consistent, fixed period of time during which the team runs through an entire lifecycle. Each sprint should run through all six stages of the DSLC, as shown below.
As I explained in an earlier post, "Data Science Team Roles," teams should be small (four to five individuals) and include a research lead, data analyst, and project manager. Although every member of the team should be asking compelling questions, the research lead is primarily responsible for that task.
One of the most effective ways to inspire and share interesting questions is via a question board— usually a large whiteboard positioned near the data science team on which team members and others in the organization post questions or challenges. The board should have plenty of open space with a short stack of sticky notes in one of the corners. You may want to include a large arrow pointing down to the stack of sticky notes with the caption, “Ask a question.”
The question board should be open to everyone in the organization, including the research lead, other data science team members, executives, managers, and employees. Try to make your question board look as enticing as possible. Anyone in the organization should be able to walk by, grab a sticky note, and post a quick question.
Given only two weeks to complete each sprint, your data science team should limit the amount of time it spends in meetings and keep those meetings focused on a specific purpose. I recommend that teams conduct five meetings over the course of a two-week sprint, each with a specific purpose and a time limit that the team agrees upon in advance:
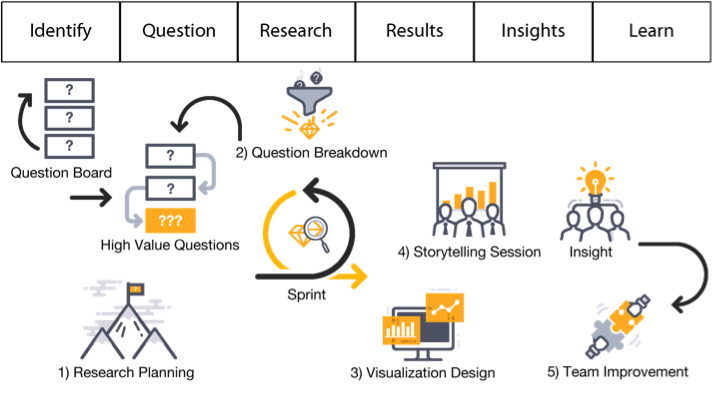
Breaking down your work involves allocating a sufficient time to all six stages of the DSLC. What often happens is that data science teams get caught up in the research stage — specifically in the process of capturing, cleaning, and consolidating the data in preparation for analysis. Given only two weeks per sprint to deliver a story, the data science team has little time to prep the data. Like agile software development teams, the data science team should look to create a minimally viable product (MVP) during its sprint — in the respect to data science, this would be a minimally viable data set, just enough data to get the job done.
Remember, at the end of a sprint, stakeholders in the organization will want to know "What do we know now that we didn't know before?" If your team gets caught up in data prep, it won't be able to answer that question.
Organizations that make significant investments in any initiative want to see a return on investment (ROI), typically in the form of a deliverable. In the world of data science, the deliverable is typically in the form of an interesting story that reveals both the meaning and the significance of the team's discoveries. Unlike a presentation or data visualization, which merely conveys what the team sees, a story conveys what the team believes. A good story provides context for understanding the data, along with guidance on how that understanding can benefit the organization.
An effective story accomplishes the following goals:
Extract Transform Load (ETL) comes from data warehousing. The ETL process is about getting data from multiple data sources and using an ETL tool to extract value.
Well established data science team roles will help your team discover insights. The data science team structure is more than just a data scientist and data engineer.
A successful data science organization will focus on widespread organizational change and not the skills of one rockstar data scientist.