Data science projects are different from software projects. Avoid the common beginner mistakes.


Businesses and other organizations typically have two types of database management systems (DBMSs) — one for online transactional processing (OLTP) and another for online analytical processing (OLAP):
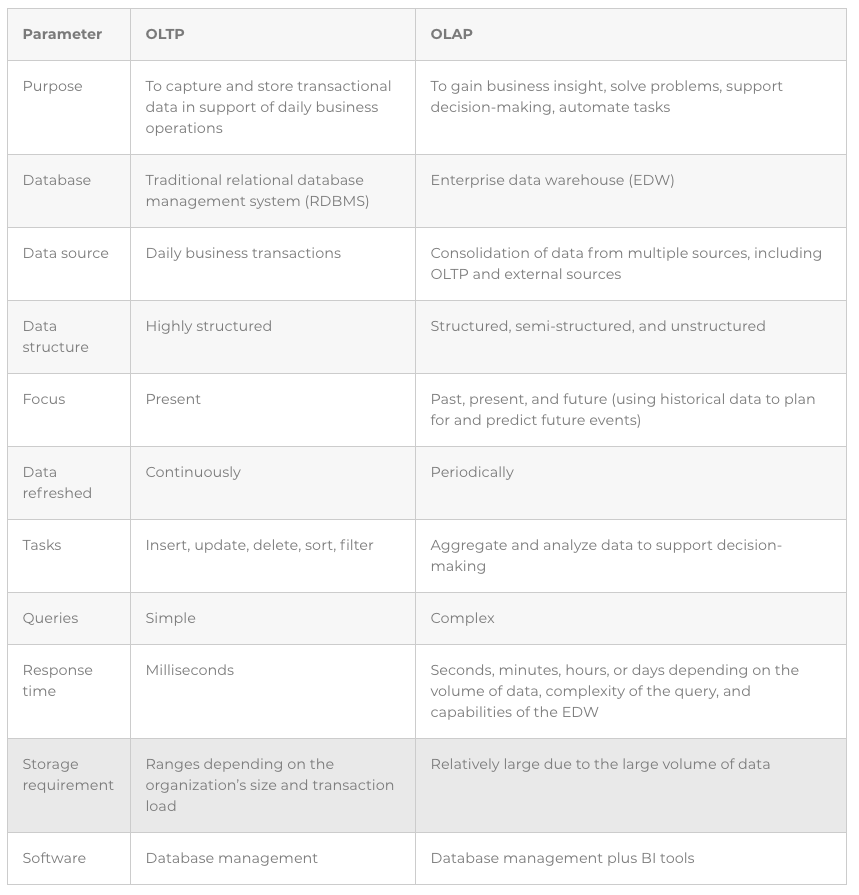
Online transactional processing (OLTP): A type of information system that captures and stores daily operational data; for example, order information, inventory transactions, and customer relationship management (CRM) details. OLTP systems are commonly used for online banking, booking flights or rooms online, ordering products online, and so on.
Online analytical processing (OLAP): A type of information system that supports business intelligence (BI) applications, such as tools for generating reports, visualizing data (with tables, graphs, maps, and so on), and conducting predictive “what if” analyses. OLAP systems are commonly used for planning, solving problems, supporting decision-making, and automating tasks (as with machine learning applications).
Traditional databases are optimized for OLTP, where the emphasis is on capturing transactional data in real time, securing transactional data, maintaining data integrity, and processing queries as quickly as possible. On the other hand, enterprise data warehouses (EDWs) are optimized for OLAP, where the emphasis is on capturing and storing large volumes of historical data, aggregating that data, and mining it for business knowledge and insights to support data-driven decision-making.
The following table highlights the differences between OLTP and OLAP
Suppose you want to sell running shoes online. You hire a database administrator (DBA) who creates dozens of different tables and relationships. You have a table for customer addresses, a table for shoes, a table for shipping options, and so on. The web server uses structured query language (SQL) statements to capture and store the transaction data. When a customer buys a pair of shoes, her address is added to the Customer Address table, the Shoes table is updated to reflect a change in inventory, the customer’s desired shipping method is captured, and so on. You want this database to be fast, accurate, and efficient. This is OLTP.
You also ask your DBA to create a script that uploads each day’s data to your EDW. You have a data analyst create a report to see whether customer addresses are related in any way to the shoes they buy. You find that people in warmer areas are more likely to buy brightly colored shoes. You use this information to change your website, so customers from warmer climates see more brightly colored shoes at the top of the page. This is an example of OLAP. While you don’t need real-time results, you do need to be able to aggregate and visualize data to extract meaning and insight from it.
Most organizations have separate OLTP and OLAP systems, and they copy data from their OLTP system to their OLAP system via a process referred to as extract, transform, and load (ETL):
For more about ETL, see my previous article Grasping Extract, Transform, and Load (ETL) Basics.
Some newer database designs attempt to combine OLTP and OLAP into a single solution, commonly referred to as a translytical database. However, OLTP systems are highly normalized to reduce redundancy, while OLAP reduces the required degree of normalization to achieve optimal performance for analytics.
Normalization is a process of breaking down data into smaller tables to reduce or eliminate the need to repeat fields in different tables. If you have the same field entries in different tables, when you update an entry in one table, you have to update it in the other; failing to do so results in a loss of data integrity. With normalization, when you need to change a field entry, such as a customer’s phone number, you have only one table in which you need to change it.
Because OLTP and OLAP differ in the degree to which data must be structured, combining the two is a major challenge. However, organizations are encountering an increasing need to analyze transactional data in real time, so the benefits of a translytical database model are likely to drive database and data warehousing technology in that direction.
Data science projects are different from software projects. Avoid the common beginner mistakes.
Artificial intelligence and organizations don't always fit together. To get the most from an AI initiative the leaders need to encourage creative questioning.
Data science is a multi-disciplinary approach to extracting insight from data. The disciplines involved include computer science/information technology, math/statistics, and domain knowledge/expertise (for example, knowledge of a specific industry). The process of extracting insight from data is typically broken down into the following five stages: Shifting the Focus from Data to Science The best way […]