The symbolic systems approach is one of the original approaches to artificial intelligence. Symbolic AI is rule-based approach that has become less popular than machine learning.


In one of my previous articles, How Machines Learn, I present a basic recipe for machine learning, including the essential ingredients and the step-by-step instructions for making it happen. One of the main ingredients is data, and sometimes lots of it. Just as people need data input to learn anything, so do machines. The key difference with machines is that the input needs to be digitized.
Another big difference is that machines are designed and built by humans, typically to perform specific tasks, such as driving a car, estimating a home's market value, recommending products, and so on. To a great degree, the purpose of the machine learning product and the data the machine needs to fulfill that purpose drive the design of the machine. The human developer needs to choose a statistical model that predicts values as close as possible to the ones observed in the data. This is called fitting model to data.
The purpose of fitting the model to the data is to improve the model's accuracy in the task it is designed to perform. Think of it as the difference between a suit off the rack and a tailored suit. With a suit off the rack, you usually have too much fabric in some areas and not enough in others. A tailored suit, on the other hand, is adjusted to match the contours of the wearer's body. Fitting the model to the data involves making adjustments to the model to optimize the accuracy of the output.
With machine learning, fitting the model involves setting hyperparameters — conditions or boundaries, defined by a human, within which the machine learning is to take place. Hyperparameters include the choice and arrangement of machine learning algorithm(s), the number of hidden layers in an artificial neural network, and the selection of different predictors.
The fine-tuning of hyperparameters is a big part of what data scientists do. They build models, run experiments on small datasets, analyze the results, and tweak the hyperparameters to get more accurate results.
Poor performance of a model can often be attributed to underfitting or overfitting:
The ultimate goal of the tuning process is to minimize bias and variance.
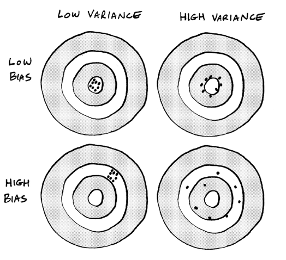
Consider a real-world example. Imagine you work for a website like Zillow that estimates home values based on the values of comparable homes. To keep the model simple, you create a basic regression chart that shows the relationship between the location of a house, its square footage, and its price. Your chart shows that big houses in nice areas have higher values. This model benefits from being intuitive. You would think that a big house in a nice area is more expensive than a small house in a rundown neighborhood. The model is also easy to visualize.
Unfortunately, this model isn't very flexible. A big house could be poorly maintained. It might have a lousy floor plan or be built on a floodplain. These factors would impact the home's value but they wouldn't be considered in the model. Because it’s not accounting for enough data, this model is likely to make inaccurate predictions; it suffers from underfitting, resulting in high bias.
To reduce the bias, you add complexity to the model in the form of additional predictors:
As you add predictors, the machine makes the model more flexible, but also more complex and difficult to manage. You solved the bias problem, but now the model has too much variance due to overfitting. As a result, the machine's predictions are off the mark for too many homes in the area.
To avoid underfitting and overfitting, you want to capture more signal and less noise:
In our Zillow example, you can capture more signal by choosing better predictors, such as number of bedrooms, number of bathrooms, quality of the school system, and so on, while eliminating less useful predictors, such as attic or basement storage. You really would need to examine the data closely to determine the factors that truly impact a home's value. In short, as the human developer, you would really need to put some careful thought into it.
The symbolic systems approach is one of the original approaches to artificial intelligence. Symbolic AI is rule-based approach that has become less popular than machine learning.
Data analysis is about asking the right questions. Good data analytics questions help your teams gain actionable insights.
The data scientist role is about discovering insights in your data by using common data science techniques.