Artificial intelligence can be a boon for people who study the humanities. There will be a greater demand for creativity and people who have training in ethics and philosophy.


Artificial neural networks learn through a combination of functions, weights, and biases. Each neuron receives weighted inputs from the outside world or from other neurons, adds bias to the sum of the weighted inputs, and then executes a function on the total to produce an output. During the learning process, the neural network weights are assigned randomly across the entire network to increase its overall accuracy in performing its task, such as deciding how likely a certain credit card transaction is fraudulent.
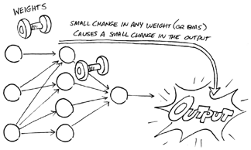
Imagine weights and biases as dials on a sound system. Just as you can turn the dials to control the volume, balance, and tone to produce the desired sound quality, the machine can adjust its dials (weights and biases) to fine-tune its accuracy. (For more about functions, weights, and bias, see my previous article, Functions, Weights, and Bias in Artificial Neural Networks.)
When you’re setting up an artificial neural network, you have to start somewhere. You could start by cranking the dials all the way up or all the way down, but then you would have too much symmetry in the network, making it more difficult for the network to learn. Specifically, if neighboring nodes in the hidden layers of the neural network are connected to the same inputs and those connections have identical weights, the learning algorithm is unable to adjust the weights, and the model will be stuck — no learning will occur.
Instead, you want to assign different values to the weights — typically small values, close to zero but not zero. (By default, the bias in each neuron is set to zero. The network can dial up the bias during the learning process and then dial it up or down to make additional adjustments.)
In the absence of any prior knowledge, a plausible solution is to assign totally random values to the weights. Techniques for generating random values include the following:
For now just think of random values as unrelated weights between zero and one but closer to zero. What’s important is that these random values provide a starting point that enables the network to adjust weights up and down to improve the artificial neural network’s accuracy. The network can also make adjustments by dialing the bias within each neuron up or down.
For an artificial neural network to learn, it requires a machine learning algorithm — a process or set of procedures that enables the machine to create a model that can process the data input in a way that achieves the network’s desired objective. Algorithms come in two types:
As a rule of thumb, use deterministic algorithms to solve problems with concrete answers, such as determining which route is shortest in a GPS program. Use non-deterministic algorithms when an approximate answer is good enough and too much processing power and time would be required for the computer to arrive at a more accurate answer or solution.
An artificial neural network uses a non-deterministic algorithm, so the network can experiment with different approaches and then adjust accordingly to optimize its accuracy.
Suppose you are training an artificial neural network to distinguish among different dog breeds. As you feed your training data (pictures of dogs and label of breeds) into the network, it adjusts the weights and biases to identify a relationship between each picture and label (dog breed), and it begins to distinguish between different breeds. Early in training, it may be a little unsure whether the dog in a certain picture is one breed or another. It may indicate that it’s 40% sure it’s a beagle, 30% sure it’s a dachshund, 20% sure it’s a Doberman, and 10% sure it’s a German shepherd.
Suppose it is a dachshund. You correct the machine, it adjusts the weights and biases, and tries again. This time, the machine indicates that it’s 80% sure it’s a dachshund, and 20% sure it’s a beagle. You tell the machine it is correct, and no further adjustment is needed. (Of course, the machine may need to make further adjustments later if it makes another mistake.)
The good news is that during the machine learning process, the artificial neural network does most of the heavy lifting. It turns the dials up and down to make the necessary adjustments. You just need to make sure that you give it a good starting point by assigning random weights and that you continue to feed it relevant input to enable it to make further adjustments.
Artificial intelligence can be a boon for people who study the humanities. There will be a greater demand for creativity and people who have training in ethics and philosophy.
Neural network gradient descent uses a different type of machine learning algorithm to help with the backpropagation of massive datasets.
In machine learning, you often have to create an ensemble by combining algorithms in your learning model.