9450 SW Gemini Drive #32865
Beaverton, Oregon, 97008-7105
Artificial neural networks learn through a combination of functions, weights, and biases. Each neuron receives weighted inputs from the outside world or from other neurons, adds bias to the sum of the weighted inputs, and then executes a function on the total to produce an output. During the learning process, the neural network weights are assigned randomly across the entire network to increase its overall accuracy in performing its task, such as deciding how likely a certain credit card transaction is fraudulent.
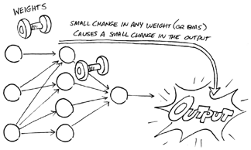
Imagine weights and biases as dials on a sound system. Just as you can turn the dials to control the volume, balance, and tone to produce the desired sound quality, the machine can adjust its dials (weights and biases) to fine-tune its accuracy. (For more about functions, weights, and bias, see my previous article, Functions, Weights, and Bias in Artificial Neural Networks.)
When you’re setting up an artificial neural network, you have to start somewhere. You could start by cranking the dials all the way up or all the way down, but then you would have too much symmetry in the network, making it more difficult for the network to learn. Specifically, if neighboring nodes in the hidden layers of the neural network are connected to the same inputs and those connections have identical weights, the learning algorithm is unable to adjust the weights, and the model will be stuck — no learning will occur.
Instead, you want to assign different values to the weights — typically small values, close to zero but not zero. (By default, the bias in each neuron is set to zero. The network can dial up the bias during the learning process and then dial it up or down to make additional adjustments.)
In the absence of any prior knowledge, a plausible solution is to assign totally random values to the weights. Techniques for generating random values include the following:
For now just think of random values as unrelated weights between zero and one but closer to zero. What’s important is that these random values provide a starting point that enables the network to adjust weights up and down to improve the artificial neural network’s accuracy. The network can also make adjustments by dialing the bias within each neuron up or down.
For an artificial neural network to learn, it requires a machine learning algorithm — a process or set of procedures that enables the machine to create a model that can process the data input in a way that achieves the network’s desired objective. Algorithms come in two types:
As a rule of thumb, use deterministic algorithms to solve problems with concrete answers, such as determining which route is shortest in a GPS program. Use non-deterministic algorithms when an approximate answer is good enough and too much processing power and time would be required for the computer to arrive at a more accurate answer or solution.
An artificial neural network uses a non-deterministic algorithm, so the network can experiment with different approaches and then adjust accordingly to optimize its accuracy.
Suppose you are training an artificial neural network to distinguish among different dog breeds. As you feed your training data (pictures of dogs and label of breeds) into the network, it adjusts the weights and biases to identify a relationship between each picture and label (dog breed), and it begins to distinguish between different breeds. Early in training, it may be a little unsure whether the dog in a certain picture is one breed or another. It may indicate that it’s 40% sure it’s a beagle, 30% sure it’s a dachshund, 20% sure it’s a Doberman, and 10% sure it’s a German shepherd.
Suppose it is a dachshund. You correct the machine, it adjusts the weights and biases, and tries again. This time, the machine indicates that it’s 80% sure it’s a dachshund, and 20% sure it’s a beagle. You tell the machine it is correct, and no further adjustment is needed. (Of course, the machine may need to make further adjustments later if it makes another mistake.)
The good news is that during the machine learning process, the artificial neural network does most of the heavy lifting. It turns the dials up and down to make the necessary adjustments. You just need to make sure that you give it a good starting point by assigning random weights and that you continue to feed it relevant input to enable it to make further adjustments.
Data science, artificial intelligence (AI), and machine learning (ML) are very complex fields. Amidst this complexity, it is easy to lose sight of the fundamental challenges to executing a data science initiative. In this article, I take a step back to focus less on the inner workings of AI and ML and more on the artificial intelligence challenges that often lead to mistakes and failed attempts at weaving data science into an organization's fabric. In the process, I explain how to overcome these key challenges.
The term "data science" is often misinterpreted. People tend to place too much emphasis on "data" and too little on "science." It is important to realize that data science is rooted in science. It is, or at least should be, exploratory. As you begin a data science program, place data science methodology at the forefront:
Even the most basic artificial neural networks require large volumes of relevant data to enable learning. While human beings often learn from one or two exposures to new data or experiences, modern neural networks are far less efficient. They may require hundreds or thousands of relevant inputs to fine-tune the parameters (weights and biases) to the degree at which the network's performance is acceptable.
To overcome this limitation, AI experts have developed a new type of artificial neural network called a capsule network — a compact group of neurons that can extract more learning from smaller data sets. As of this writing, these networks are still very much in the experimental phase for most organizations.
Until capsule networks prove themselves or some other innovation enables neural networks to learn from smaller data sets, plan on needing a lot of high-quality, relevant data.
If you are lacking the data you need, consider obtaining data from external sources. Free data sources include government databases, such as the US Census Bureau database and the CIA World Factbook; medical databases, such as Healthdata.gov, NHS health, and the Social Care Information Centre; Amazon Web Services public datasets; Google Public Data Explorer; Google Finance; the National Climatic Data Center; The New York Times; and university data centers. Many organizations that collect data, including Acxiom, IRI, and Nielsen, make their data available for purchase. As long as you can figure out which data will be helpful, you can usually find a source.
There are two approaches to machine learning — supervised and unsupervised learning. With supervised learning, you need two data sets — a training data set and a testing data set. The training data set contains inputs and labels. For example, you feed the network a picture of an elephant and tell it, "This is an elephant." Then, you feed it a picture of a giraffe and tell it, "This is a giraffe." After training, you switch to the testing data set, which contains unlabeled inputs. For example, you feed the network a picture of an elephant, and the network tells you, "It's an elephant." If the network makes a mistake, you feed it the correct answer, and it makes adjustments to improve its accuracy.
Sometimes when a data science team is unable to acquire the volume of data it needs to train its artificial neural network, the team mixes some of its training data with its test data. This workaround is a big no-no; it is the equivalent of giving students a test and providing them with the answers. In such a case, the test results would be a poor reflection of the students' knowledge. In the same way, an artificial neural network relies on quality testing to sharpen its skills.
The moral of this story is this: Don’t mix test data with training data. Keep them separate.
When choosing training and test data for machine learning, select data that is representative of the task that the machine will ultimately be required to perform. If the training or test data is too easy, for example, the machine will struggle later with more challenging tasks. Imagine teaching students to multiply. Suppose you teach them multiplication tables up to 12 x 12 and then put problems on the test such as 35 x 84. They’re not going to perform very well. In the same way, training and test data should be as challenging as what the machine will ultimately be required to handle.
Also, avoid the common mistake of introducing bias when selecting data. For example, if you’re developing a model to predict how people will vote in a national election and you feed the machine training data that contains voting data only from conservative, older men living in Wyoming your model will do a poor job of predicting the outcome.
Machine learning is a powerful tool, but it’s not always the best tool for answering a question or solving a problem. Here are a couple other options that may lead to better, faster outcomes depending on the nature of the question or problem:
As you introduce data science, artificial intelligence, and machine learning to your organization, remain aware of the key challenges you face, and avoid getting too wrapped up in the technologies and toolkits. Focus on areas that contribute far more to success, such as asking interesting questions and using your human brain to approach problems logically. Artificial intelligence and machine learning are powerful tools. Master the tools; do not let them master you.
Artificial intelligence and organizations are not always a great fit. While many organizations use artificial intelligence to answer specific questions and solve specific problems, they often overlook its potential as a tool for exploration and innovation — to look for patterns in data that they probably would not have noticed on their own. In these organizations, the focus is on supervised learning — training machines to recognize associations between inputs and labels or between independent variables and the dependent variable they influence. These organizations spend less time, if they spend any time at all, on unsupervised learning — feeding an artificial neural network large volumes of data to find out what the machine discovers in that data.
With supervised learning, data scientists are primarily engaged in a form of programming, but instead of writing specific instructions in computer code, they develop algorithms that enable machines to learn how to perform specific tasks on their own — after a period of training and testing. Many data science teams today focus almost exclusively on toolkits and languages at the expense of data science methodology and governance.
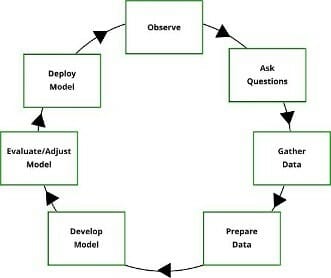
Data science encompasses much more than merely training machines to perform specific tasks. To achieve the full potential of data science, organizations should place the emphasis on science and apply the scientific method to their data:
Note that the first step in the scientific method is to observe. This step is often overlooked by data science teams. They start using the data to drive their supervised machine learning projects before they fully understand that data.
A better approach is exploratory data analysis (EDA) — an approach to analyzing data sets that involves summarizing their main characteristics, typically through data visualizations. The purpose of EDA is to find out what the data reveals before conducting any formal modeling or testing or hypothesis about the data.
Unsupervised learning is an excellent tool for conducting EDA, because it can analyze volumes of data far beyond the capabilities of what humans can analyze, it looks at the data objectively, and it provides a unique perspective on that data often revealing insights that data science team members would never have thought to look for.
Note that the second step in the scientific method is to question. Unfortunately, many organizations disregard this step, usually because they have a deeply ingrained control culture — an environment in which leadership makes decisions and employees implement those decisions. Such organizations would be wise to change from a control culture to a culture of curiosity — one in which personnel on all levels of the organization ask interesting questions and challenge long-held beliefs.
People are naturally curious, but in some organizations, employees are discouraged from asking questions or challenging long-held beliefs. In organizations such as these, changing the culture is the first and most challenging step toward taking an exploratory approach to artificial intelligence, but it is a crucial first step. After all, without compelling questions, your organization will not be able to reap the benefits of the business insights and innovations necessary to remain competitive.
In one of my previous posts Asking Data Science Questions, I present a couple ways to encourage personnel to start asking interesting questions:
Another way to encourage curiosity is to reward personnel for asking interesting questions and, more importantly, avoid discouraging them from doing so. Simply providing public recognition to an employee who asked a question that led to a valuable insight is often enough to encourage that employee and others to keep asking great questions.
The takeaway here is that you should avoid the temptation to look at artificial intelligence as just another project. You don’t want your data science teams merely producing reports on customer engagement, for example. You want them to also look for patterns in data that might point the way to innovative new ideas or to problems you weren’t aware of and would never think to look for.
In my previous article How Machines Learn, I list the essential ingredients needed for the ways machines learn. Here is the basic 5-step process that enables machines to learn. I also mention two types of machine learning — supervised and unsupervised. In this post, I do a deeper dive into these two types of machine learning, along with a third — reinforcement learning. First, let's take a look at how people learn.
People learn in all sorts of ways — through reading, listening, observing, sensing, feeling, playing, interacting, comparing, experiencing, reasoning, teaching, trial and error, and so on. Psychic Edgar Cayce claimed he learned how to spell by sleeping with his spelling book under his pillow. And all of those learning methods I just mentioned merely scratch the surface. Scientists are still trying to figure out how the brain works and identify the many ways the brain functions to learn new things.
Imagine you want to learn how to play checkers. You could do this in several different ways. You could hire a tutor, who would introduce you to the game, teach you how to move the checkers, and show you some winning strategies. You could practice by playing against the tutor, who would supervise your moves and perhaps correct you when you make a foolish mistake. As you increase your mastery of the game, you would then be able to play without supervision and even develop your own strategies.
Another option would be to watch people play checkers. By closely observing how others play the game, you could probably figure out how to move the checkers, how to jump an opponent's checkers, how to earn a crown, and so forth. You would probably also start to identify different strategies for winning.
You might even try a combination of these two approaches. A tutor would bring you up to speed on the basics — how to set up the board, move the checkers, jump an opponent's checkers, earn a crown, and so forth — and then you'd observe other people playing. You'd have a high-level overview of the game, but you'd rely on your own observations to learn new strategies and improve your game.
The three ways to learn to play checkers are very similar to how machines often learn:
Reinforcement learning is a technique that involves rewarding the machine for its performance. Reinforcement learning has its roots in operant conditioning — the principle that behavior followed by pleasant consequences is likely to be repeated, and behavior followed by unpleasant consequences is less likely to be repeated. With reinforcement learning, a reward is associated with a certain action or occurrence, and an environment is created in which the machine attempts to maximize its cumulative reward.
In 2013 Google's DeepMind project produced an application of reinforcement learning its developers called Q-learning. In Q-learning, you have a set environments or states typically represented by the letter "S," possible actions that can respond to the states represented by the letter "A," and quality of performance represented by the letter "Q."
Suppose you have an Atari game like Space Invaders that requires you to blast aliens with your laser cannon as they descend from the sky. To help the computer learn how to play, you might have S represent the number of aliens descending and the speed of descent and A represent actions the computer takes to shoot aliens out of the sky, thus improving Q, which represents the score of the game. Each time the computer successfully shoots down an alien, it's rewarded with an increase in Q. The machine plays the game repeatedly and, attempting to maximize Q, becomes much more adept at shooting down aliens.
Reinforcement learning, specifically Q-Learning, enables machines to quickly grow beyond our understanding. It can help you skip the steps required for collecting data and then feeding the machine training data and test data. The machine essentially creates its own data as it engages in iterative trial and error.
While supervised, unsupervised, semi-supervised, and reinforcement learning are the primary ways machines learn, stay tuned for more to come. Experts in artificial intelligence (AI) are constantly working on developing new approaches to machine learning and understanding how to combine different techniques.
You have data, and you have questions to answer and problems to solve. How do you go about using your data to answer those questions and solve those problems? Due to the power and popularity of big data, machine learning (ML), and artificial intelligence (AI), many organizations leap to the conclusion that choosing machine learning is the best approach. However, older, less sophisticated options may deliver better results, depending on the purpose. Sometimes, a spreadsheet or database program is all you need.
The following is a list of options along with suggestions of when each option may be most appropriate for any given data product:
When you're trying to decide between machine learning and an expert system, ask the following question: Does the task require sequential reasoning or pattern matching? If it requires sequential reasoning and the task can be mapped out, go with an expert system. If it requires pattern matching, either to make a prediction or to help uncover hidden meaning in the data, machine learning is probably best.
Prior to deciding which approach is the best match for the problem you're trying to solve or the question you're trying to answer, consult your data science team. Other people on the team may be able to offer valuable insights based on their unique perspectives and training. Encourage your team to ask questions, so they begin to develop an exploratory mindset. Team members should challenge one another's ideas and recommendations, so, together, the team can choose the best approach. (During this process, you may even discover that the question or problem you have identified is not the one you should be seeking to answer or solve. Instead, there may be a more compelling path to explore.)
Keep in mind that two distinctly different approaches may be effective in answering the question or solving the problem, and that a combination of approaches (an ensemble) may be the best approach. If two different approaches seem to be equally effective, opt for the easiest, most cost-effective option.
What is important is that you and your data science team carefully consider the different approaches before starting your work. Choosing the right approach and the right tools will make your job that much easier and deliver superior results.
In a previous article What Is Machine Learning? I present a brief history of machine learning and discuss how machine learning developed as a way to overcome certain limitations in the early days of artificial intelligence. Without the ability to learn, early developers could make machines do only what they were told or programmed to do. Machine learning expands their capabilities beyond what they are merely programmed to do.
When people first encounter the concept of machine learning, they often wonder how machines learn? We are accustomed to working with software that is written to program machines to interact with humans via keyboard, mouse, display screen, microphone, and speakers. We may have even noticed some mock forms of machine learning, such as programs that rearrange menu options based on the frequency with which the user chooses certain commands. However, learning how to distinguish between objects and adapt to one's environment involves complexity of another scale entirely, which makes people wonder, "How can machines possibly do that?"
Programming involves writing code that tells a machine, in a digital language, how to perform specific tasks. All you need is a machine that understands the programming language and instructions (software) written in that language. Machine learning requires a more complex combination of ingredients:
The machine learning process is complicated and varies considerably based on the task and the type of learning (supervised or unsupervised), but it generally follows these steps:
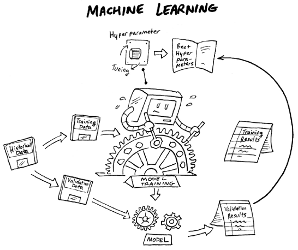
1. A human participant sets the hyperparameters, which involves deciding on the number and arrangement of artificial neurons, choosing a machine learning algorithm, and so on.
2. The human participant feeds the machine input data. The data type varies depending on whether the machine is engaging in supervised or unsupervised learning:
3. Using the algorithm, the machine performs calculations on the inputs, adjusting the parameters as necessary:
4. As it processes the inputs (or input-output pairs), the machine creates a model that consists of the algorithm and parameters required to calculate outputs based on the given inputs (supervised learning) or figure out which group an input belongs to (unsupervised learning).
5. When you feed the machine inputs, it has learned how to process those inputs to deliver the correct (or most likely to be correct) outputs.
Learning does not necessarily stop at Step 5. It may continue for as long as the model is in use, fine-tuning itself to produce more accurate outputs. For example, if you have a model that distinguishes spam from not-spam, every time a user moves a message from the Spam folder to the Inbox or vice versa, the machine adjusts the model in response to the correction.
Suppose you have the following input-output pairs showing a direct correlation between the size of houses and their prices:
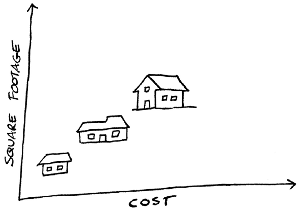
1,000 square feet = $50,000
1,500 square feet = $75,000
2,000 square feet = $100,000
2,500 square feet = $125,000
If you were to graph these values, you'd get a straight line, and this line could be described using the linear equation (algorithm) y = mx + b, where x is square footage (input), y is price (output), m is the slope of the line and b is the point at which the line crosses the y axis. In this algorithm, m and b are the parameters. Given the inputs and outputs, the slope of the line (m) is 1 and the line crosses the y-axis at 0 (zero). So the machine's initial model would be y = 1x + 0.
Now suppose the machine were fed an input-output pair of 3,000 square feet = $175,000. If you were to plot that point on the graph, you would see that it is not on the line, so the machine's model is not 100% accurate.
To fix the model, the machine can adjust one or both parameters. It can change the slope of the line (m) or the y-intercept (b) or change both. That's how the machine "learns" with supervised learning.
In an interesting post on HackerNoon.com entitled Is Another AI Winter Coming?, Thomas Nield argues that the expectations for artificial intelligence (AI) may exceed its potential, and that if we do not "temper our expectations and stop hyping 'deep learning' capabilities . . . we may find ourselves in another AI Winter." He expects the growing skepticism over AI capabilities to "go mainstream as soon as 2020."
Although AI does seem overhyped in some circles, I doubt an AI Winter is coming any time in the near future, if ever. I base this doubt on the following points:
AI winter is a period of time during which interest in and funding for AI research slumps. The two major AI winters occurred in 1974–1980 and 1987–1993 due to disappointing results that led to decreased funding for research.
Each of these periods was preceded by an AI Spring — a period of significant activity and progress in the field. The first spring occurred in 1956—1974, a period that included the invention of the perceptron by Frank Rosenblatt in 1958, along with several computers that were able to solve algebra word problems, prove theorems in geometry, and speak English. The second AI spring occurred in 1980–1987, a period which coincided with the development of the first expert systems based on the physical symbol system, developed by Allen Newell and Herbert A. Simon.
We are currently experiencing an AI spring, which began in 1993, primarily due to the development of the intelligent agent — an autonomous entity that perceives its environment and acts accordingly; for example, a self-driving car. The current spring gained momentum in the early 2000s with advances in machine learning and statistical AI along with increased availability of big data and significant increases in processing power.
Whether AI is overhyped depends on how you define "artificial intelligence." If you define it as a machine's ability to perform tasks traditionally thought to require human intelligence, then we have already achieved AI. We now have self-driving cars, automated investment advisors, and systems that are more accurate than doctors at diagnosing cancer and other diseases in patients.
However, if you define AI as a machine or computer system that possesses self-consciousness and self-determination, then AI may be unattainable. We may never see robots that think like humans. In that sense, we may be in a perpetual AI winter characterized by periods of booms and busts in research funding.
Nearly every ground-breaking technology experiences ebbs and flows. A few meet or even exceed expectations, and some never do. I think AI is somewhat different. I like to compare it to space exploration, in which, it seems to me, the journey is more important than the destination.
Maybe AI is a pipe dream — an unattainable goal. But maybe that's unimportant. Maybe this unattainable goal that we foolishly believe is attainable is the inspiration that motivates us to explore. As such, that is good enough, because in our drive to achieve the unattainable, we improve the human condition through increased knowledge and skills, amazing new technologies, and innovative products.
I think we have learned that lesson over the years — over the course of the several AI springs and winters — and I believe that having learned this lesson will make a future AI winter much less likely.
In my previous articles What Are Machine Learning Algorithms and Choosing the Right Machine Learning Algorithm, I describe several commonly used machine learning algorithms and provide guidance for choosing the right one based on the desired use case and other factors.
However, you are not limited to using only one machine learning algorithm in a given application. You also have the option of combining machine learning algorithms through various techniques referred to collectively as ensemble modeling. One option is to combine the outcomes of two or more algorithms. Another option is to create different data samples, feed each data sample to a machine learning algorithm, and then combine the two outputs to make a final decision. In this post, I explain the three approaches to ensemble modeling — bagging, boosting, and stacking.
Bagging involves combining the outputs from two or more algorithms with the goal of improving the accuracy of the final output. Here's how it works:

The bagging approach results in reduction of variance, which in turn may improve the overall accuracy of the output in comparison to using a single tree.

Boosting involves one or more techniques to help algorithms accurately classify inputs that are difficult to classify correctly. One technique involves combining algorithms to increase their collective power. Another technique involves assigning the characteristics of challenging data objects greater weights or levels of importance. The process runs iteratively, so that the machine learns different classifiers by re-weighting the data such that the newer classifiers focus more on the characteristics of the data objects that were previously misclassified.
Like bagging, boosting results in reduction of variance, but boosting can be sensitive to outliers — inputs that lie outside the range of the other inputs. Adjusting for the outliers may actually reduce its accuracy.
Stacking involves using two or more different machine learning algorithms (or different versions of the same algorithm) and combining their outputs using another meta-learner to improve the classification accuracy.
The team that won the Netflix prize used a form of stacking called feature-weighted linear stacking. They created several different predictive models and then stacked them on top of each other. So you could stack K-nearest neighbor on top of Naïve Bayes. Each one might add just .01% more accuracy, but over time a small increase in accuracy can result in significant improvement. Some winners of this machine learning competition stacked 30 algorithms or more!
Think of ensemble modeling as the machine learning version of "Two heads are better than one." Each of the techniques I describe in this post involve combining two or more algorithms to increase the total accuracy of the model. You can also think of ensemble modeling as machine learning's way of adding brain cells — by strategically combining algorithms, you essentially raise the machine's IQ. Keep in mind, however, that you need to give careful thought to how you combine the algorithms. Otherwise, you may end up actually lowering the machine's prediction abilities.
Some people are afraid of machine learning and artificial intelligence (AI), and some of those people who are most afraid of artificial intelligence work in the AI field. As for me, I don't fear AI itself as much as I fear what people might do with it. In fact, most AI fears stem from questions about its ethical use (by people). In this post, I cover these fears and a few others.
We are already seeing early warning signs of AI abuse at the national level. According to a report in The New York Times, "Chinese start-ups have built algorithms that the government uses to track members of a largely Muslim minority group" through the use of facial recognition technology. Along with its expansive network of surveillance cameras, China uses facial recognition technology to identify Uighurs (members of the Muslim minority) and then keeps a record of where they go, what they do, and the people they associate with, so this information can be searched and reviewed.
Given that China has already held as many as a million Uighurs in detention camps, the use of technology to single out and monitor Uighurs more closely is an alarming development. As NY Times reporter Paul Mozur puts it, "The practice makes China a pioneer in applying next-generation technology to watch its people, potentially ushering in a new era of automated racism."
Big data and machine learning may also drive more subtle forms of discrimination. For example, lenders, insurance providers, employers, and colleges might use the insights gleaned from big data to deny mortgage loans, insurance coverage, jobs, or college admission to certain applicants based on their online search history, spending patterns, products they purchased, or even the types of books they read or music they listen to.
Big data and machine learning are primarily responsible for enabling personalization — products and services tailored for each user's needs and preferences. Search engines personalize your search results to make them more relevant to your interests and location. GPS personalizes directions to a destination based on your current location. Facebook can notify you if any of your Facebook friends happen to be nearby. Netflix can recommend movies based on your browsing history.
While there is certainly nothing to fear about these applications of big data and machine learning, the threat to personal privacy raises concern, particularly if personal data is not anonymized — which may not be entirely possible. (Anonymization of data involves removing any data that could be used to identify an individual, such as the person's name, address, phone number, social security number, and driver's license number.)
Loss of privacy is such a big concern that governments are developing legislation to protect privacy. For example, in the European Union, the General Data Protection Regulation (GDPR) protects the privacy of all individual citizens in the EU and the European Economic Area. The GDPR even contains a "right to be forgotten" clause, enabling individuals to have their personal data deleted upon request, providing there are no legal grounds for retaining it.
One of the top AI fears is that automation will eliminate so many jobs that unemployment will become a bigger problem than it already is. Countries around the world are trying to lessen the impact by preparing their workforce for higher-level jobs that AI is ill-equipped to handle. However, it remains to be seen whether the creation of new jobs will keep pace with the loss of old ones. In addition, not everyone is geared to fill the job openings of the future, which generally require more education, skill, and talent than those that technology is eliminating.
Related to unemployment is the resulting financial inequality. As more jobs are automated, the people who benefit most financially are those who own the machines. As a result, the rich get richer, the poor get poorer, and now a large portion of the middle class become poor.
Governments attempt various ways to distribute income through taxes and social programs (taking from the rich to give to the poor), but simply redistributing wealth can lead to a host of other socio-economic problems.
The question is how we can all benefit when the workload shifts from humans to robots. Ideally, we should all have more time for leisure and higher level pursuits, such as art, literature, and philosophy. Unfortunately, the resulting financial inequality more often than not results in increased suffering and crime.
Doomsday scenarios in which robots develop self-awareness and self-determination and turn against humans certainly give rise to some AI fears, but these are still solidly in the realm of science fiction. Currently, and in the foreseeable future, robots still pretty much do what they're told. Machine learning enables them to hone certain skills, such as the ability to communicate in spoken language, but they are not even aware they are doing so. Natural language processing (NLP) is still largely an exercise in pattern-matching.
The biggest threat in this area comes from heavy-duty robotic machinery that people accidentally get too close to. Many robots operate inside cages to avoid such accidents. However, even in this application of AI, developers are working toward making robots safer — for example, enabling robots to detect animate beings nearby, so they can automatically shut themselves down to prevent injury.
Of course, the law of unintended consequences holds true in AI as it does in other areas of complexity. What experts fear about rogue robots is related to the fear of unintended consequences; for example, artificial neural networks that become so complex that robots become self-aware and self-directed and decide that humans need to be enslaved or wiped off the face of the planet. In addition, there could be unintended consequences that produce outcomes we have yet to imagine.
So, the short answer to the question Should we be afraid of artificial intelligence? is yes. But keep in mind that AI is a tool, which, like many powerful tools, can be used or abused. As long as we are aware of the threats and address them appropriately, I think we have little to fear and great progress to look forward to.
In my previous article The Different Ways Machines Learn, I described the four common approaches to machine learning:
Within these different approaches, developers use a variety of machine-learning algorithms (An algorithm is a set of rules for solving a problem in a fixed number of steps). So what are machine learning algorithms? Common machine-learning algorithms include decision trees, K-nearest neighbor, K-means clustering, regression analysis, and naïve Bayes, all of which I describe in this post.
A decision tree is a flow chart for choosing a course of action or drawing a conclusion. They are often used to solve binary classification problems; for example, whether to approve or reject a loan application.

Suppose you wanted to create a decision tree to predict whether or not someone will go to the beach. To create your decision tree, you might start with Sky, which branches off into three possible conditions: Sunny, Rainy or Overcast. Each of these conditions may or may not branch off to additional conditions; for example, Sunny branches off to “85° or Above” and “Below 85°,” and Overcast branches off to “Weekend” and “Weekday.” Making a decision is a simple matter of following the branches of the tree; for example, if the day is sunny and above 85°, Joe goes to the beach, but if the sky is overcast and it’s a weekday, Joe doesn’t go to the beach.
Decision trees are useful for binary classification — when there are only two choices, such as Joe goes or doesn’t go to the beach, a loan application is approved or rejected, or a transaction is fraudulent or not.
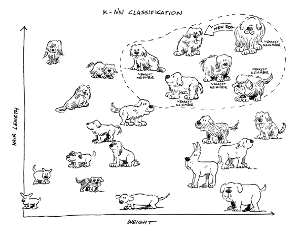
The K-nearest neighbor algorithm classifies data based on similarities, making it very useful for multi-class classification. With K-nearest neighbor, you essentially chart points on a graph that represent known things with certain characteristics, and then identify groups of points that are nearest to each other (the nearest neighbors). The K represents the number of nearest neighbors. K = 1 means only 1 nearest neighbor. K = 2 means two nearest neighbors. The higher the K value, the broader the category or class.
Another very common machine learning algorithm is K-means clustering, which is often confused with K-nearest neighbor (KNN). However, while K-nearest neighbor is a supervised machine learning algorithm, K- means clustering is an unsupervised machine learning algorithm. Another difference is that the K in K-nearest neighbor represents the number of nearest neighbors used to classify inputs, whereas the K in K-means clustering represents the number of groups you want the machine to create.
For example, suppose you have dozens of pictures of dogs, and you want the machine to create three groups with similar dogs in each group. With unsupervised learning, you don’t create the groups — the machine does that. All you do is tell the machine to create three groups, so K = 3.
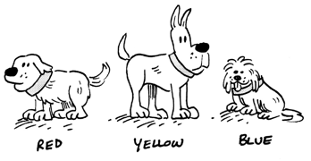
It just so happens that all the dogs have collars and each collar is either red, yellow, or blue. The machine focuses on the collars and creates three groups — one for each color — and assigns dogs to each of those groups based on the color of their collars.
Regression analysis looks at the relationship between predictors and outcomes in an attempt to make predictions of future outcomes. (Predictors are also referred to as input variables, independent variables, or even regressors.) With machine learning (supervised learning to be precise), you feed the machine training data that contains a small collection of predictors and their associated known outcomes, and the machine develops a model that describes the relationship between predictors and outcomes.
Linear regression is one of the most common types of machine learning regression algorithms. With linear regression you want to create a straight line that shows the relationship between predictors and outcomes. Ideally you want to see all your different data points closely gathered around a straight line, but not necessarily touching the line or on the line.
For example, you could use linear regression to determine the relationship between the outdoor temperature and ice cream sales.
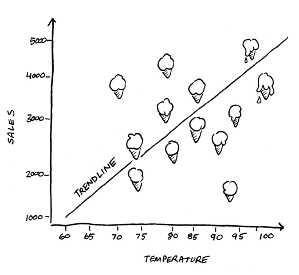
You can see a very clear trendline in this scatterplot diagram; the higher the temperature the greater the ice cream sales. You can also see a few outliers — data points that are far away from the trendline. This could be due to a local festival or because someone had scheduled a birthday gathering at the shop that day. Having a lot of outliers makes it much more difficult to use linear regression to predict ice cream sales.
Naïve Bayes differs considerably from the machine learning algorithms covered so far. Instead of looking for patterns among predictors, naïve Bayes uses conditional probability to determine the likelihood of something belonging to a certain class based on each predictor independent of the others. It's called naïve because it naïvely assumes that the predictors aren't related.
For example, you could use a naïve Bayes algorithm, to differentiate three classes of dog breeds — terrier, hound, and sport dogs. Each class has three predictors — hair length, height, and weight. The algorithm does something called class predictor probability. For each predictor, it determines the probability of a dog belonging to a certain class.
For example, the algorithm first checks the dog's hair length and determines that there's a 40% chance the dog is a terrier, a 10% chance it's a hound and a 50% chance it's a sport dog. Then, it checks the dog's height and determines that there's a 20% chance the dog is a terrier, a 10% chance it's the hound and a 70% chance it's a sport dog. Finally, it checks the dog's weight and figures that there's a 10% chance that the dog is a terrier, a 5% chance that it's a hound and an 85% chance that it's a sport dog. It totals the probabilities, perhaps giving more weight to some than others, and, based on that total, chooses the class in which the dog is most likely to belong.
Naïve Bayes gets more complicated, but this is generally how it works.
One of the critical steps in any attempt at machine learning is to choose the right algorithm or combination of algorithms for the job, but I will reserve that topic for future posts.